

智能语音设备需要在远场噪声环境中,仍具备出色的语音交互性能,声学前端 (Audio Front-End, AFE) 算法在构建此类语音用户界面 (Voice-User Interface, VUI) 时至关重要。乐鑫 AI 实验室自主研发了一套乐鑫 AFE 算法框架,可基于功能强大的 ESP32 和 ESP32-S3 SoC 进行声学前端处理,使用户获得高质量且稳定的音频数据,从而构建性能卓越且高性价比的智能语音产品。
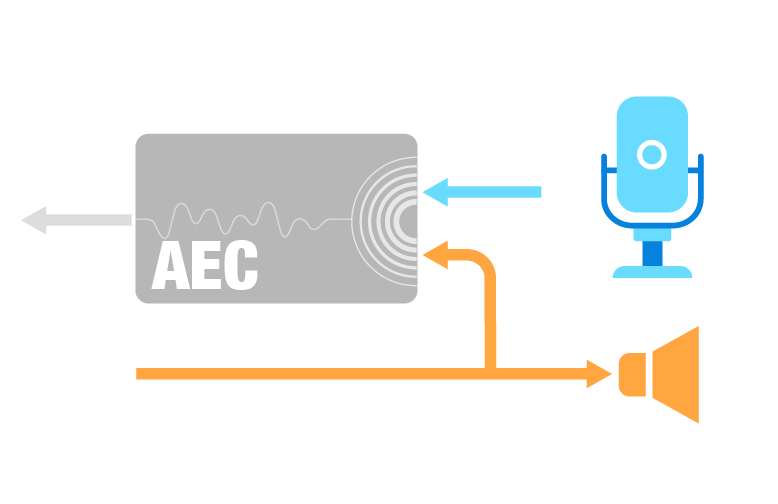
声学回声消除 (AEC)
声学回声消除算法通过自适应滤波的方法,消除使用麦克风输入音频时的回声。此算法适用于语音设备通过扬声器播放音频等场景。
盲源分离 (BSS)
盲源分离算法使用多个麦克风检测传入音频的方向,并强化某个方向的音频输入。此算法在噪音环境中提高了所需音频源的声音质量。

噪声抑制 (NS)
噪声抑制算法支持单通道音频信号处理,能够有效消除无用的非人声(如吸尘器或空调声),从而改善所需处理的音频信号。
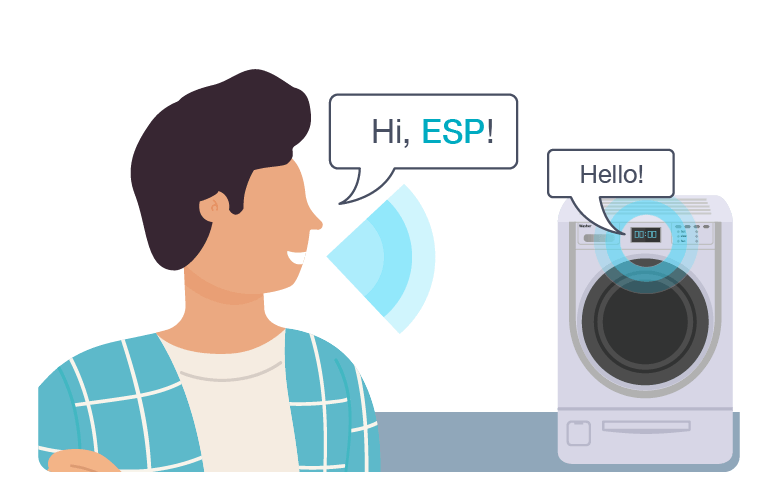
唤醒词引擎 (WakeNet)
WakeNet 是乐鑫自研的高性能、低资源消耗的唤醒词检测算法,能够使设备对“Alexa”、“嗨 乐鑫”和“Hi, ESP”等唤醒词做出反馈。
算法优势

声学性能优越
乐鑫 AFE 算法已通过亚马逊 Alexa 远场测试。算法中使用了乐鑫自研唤醒词引擎 WakeNet,可满足亚马逊对多语言的测试要求。

资源消耗低
乐鑫 AFE 算法基于 ESP32-S3 SoC 的 AI 加速器进行了优化,仅消耗约 22% CPU 空间、48 KB SRAM 和 1.1 MB PSRAM,为使用 ESP32-S3 构建的客户应用提供了充足的资源空间。

产品设计灵活
乐鑫 AFE 算法提供了简单且直观的 API 接口,方便客户根据需要,动态调整产品性能。此外,它还支持 20-80 mm 的麦克风间距,为客户产品的硬件设计提供了相当大的灵活性。
亚马逊认证的 Audio Front End 方案
乐鑫 AFE 算法已通过亚马逊 Alexa 内置设备的 Audio Front End 认证。算法通过 ESP32-S3 的 AI 加速器进行了优化,与硬件结合后,仅使用两个麦克风即可实现 360 度拾音。





